Google turboalimenta su motor GenAI con Gemini 1.5
hace 2 semanas

Apenas una semana después de enviar Gemini 1.0, Google comenzó a probar la versión 1.5 de su modelo multimodal genAI y su capacidad para comprender un contexto prolongado de más de un millón de tokens.
Antes del fin de semana, Google presentó Gemini 1.5, su próximo modelo de inteligencia artificial generativa (genAI) destinado a suceder a la versión 1.0 lanzada una semana antes. Según la compañía, la futura versión del modelo de IA multimodal, ya lista para sus primeras pruebas, supera a la anterior en casi todos los sentidos. A diferencia del popular ChatGPT de OpenAI, los usuarios pueden introducir una cantidad mucho mayor de información en su motor de consultas para obtener respuestas más precisas. Tenga en cuenta que OpenAI también anunció un modelo de IA el jueves pasado llamado Sora. Este modelo de texto a video es capaz de generar escenas de video complejas con múltiples personajes, tipos de movimiento específicos y detalles precisos del sujeto y del fondo "mientras mantiene la calidad visual y la adherencia al mensaje del video". el usuario ". El modelo de OpenAI incluye no solo lo que el usuario preguntó en el mensaje, sino también cómo existen esas cosas en el mundo físico.

Una escena de película generada por el motor GenAI Sora, de OpenAI (Crédito: OpenAI).
Los modelos Gemini de Google son los únicos modelos de lenguaje grande (LLM) multimodales nativos de la industria. Gemini 1.0 y Gemini 1.5 pueden ingerir y generar contenido en forma de texto, imágenes, audio, video y mensajes de código. Por ejemplo, en el modelo Gemini, las indicaciones del usuario pueden tener la forma de imágenes Jpeg, WEBP, HEIC o HEIF. “Tanto OpenAI como Gemini reconocen la importancia de la multimodalidad y la abordan de diferentes maneras. Recordemos que Sora es sólo un modelo preliminar, con disponibilidad limitada, y no estará disponible de forma generalizada en el corto plazo”, dijo Arun Chandrasekaran, analista de Gartner. "Sora de OpenAI competirá con startups como Runway AI, creadores de modelos de conversión de texto a vídeo", añadió.
Anunciado por primera vez en diciembre de 2023, Gemini 1.0 se lanzó la semana pasada. En esta ocasión, Google declaró que había reconstruido y renombrado su chatbot Bard. Gemini es lo suficientemente flexible como para trabajar en todo, desde centros de datos hasta dispositivos móviles. Y según Chirag Dekate, analista de Gartner, si ChatGPT 4, el último LLM de OpenAI, es multimodal, sólo ofrece algunas modalidades de imágenes y texto o texto a vídeo. “Google quiere desempeñar su papel como proveedor líder de servicios de inteligencia artificial en la nube. Ya no se trata de recuperar el tiempo perdido. Otros han empezado a involucrarse en esto”, dijo Dekate. "Hoy en día, un usuario registrado de Google Cloud puede acceder a más de 132 modelos, cuya amplitud es asombrosa", afirmó. "Las industrias verticales como los medios y el entretenimiento podrían ser las primeras en adoptar modelos como este, y las compañías y empresas de tecnología también podrían ser las primeras en adoptar funciones comerciales como funciones de marketing y diseño", dijo. dijo el señor Chandrasekaran. Actualmente, OpenAI está trabajando en la próxima generación GPT 5 de su modelo, que también debería ser multimodal. Dekate cree, sin embargo, que GPT 5 constará de varios modelos pequeños ensamblados y que no será multimodal de forma nativa y, por lo tanto, su arquitectura probablemente será menos eficiente.
El primer modelo Gemini 1.5 que Google ofrece para pruebas preliminares se llama Gemini 1.5 Pro, que la compañía describe como "un modelo multimodal de tamaño mediano optimizado para escalar en una amplia gama de tareas". "El rendimiento de este modelo es similar al del Gemini 1.0 Ultra, el modelo más grande de Google hasta la fecha, pero requiere muchos menos ciclos de GPU", dijo la compañía. Gemini 1.5 Pro también presenta una función experimental de comprensión de contexto prolongado que permite a los desarrolladores solicitar hasta 1 millón de tokens de contexto del motor. Los desarrolladores pueden registrarse para obtener la vista previa privada de Gemini 1.5 Pro en Google AI Studio. Google AI Studio es la forma más rápida de crear modelos Gemini y para que los desarrolladores integren la API de Gemini en sus aplicaciones. Está disponible en 38 idiomas en más de 180 países y territorios.
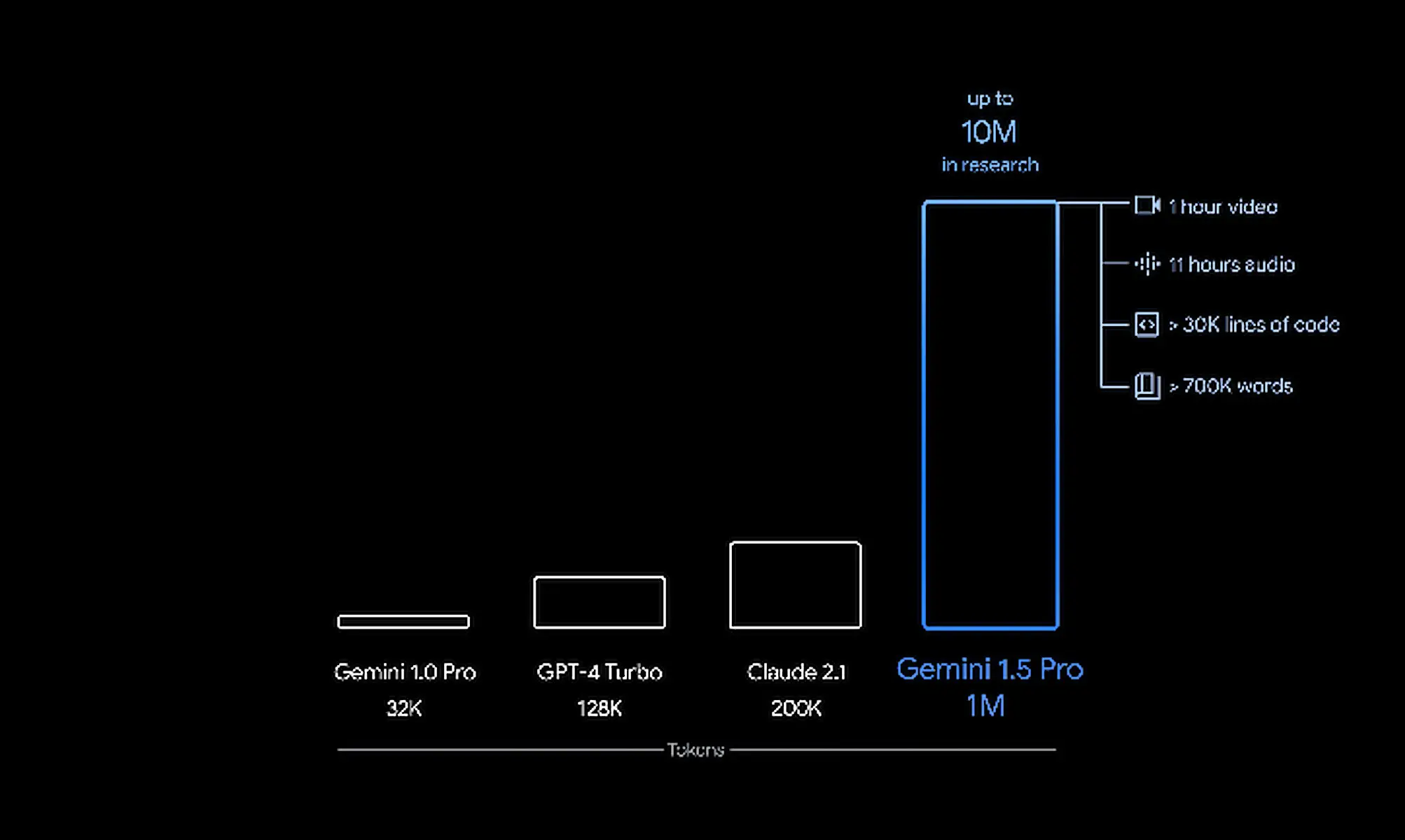
Comparación entre Gemini 1.5 y otros modelos de IA en términos de ventanas emergentes de tokens. (Crédito: Google)
El modelo Gemini de Google fue diseñado desde cero para ser multimodal y no se compone de varias partes una encima de la otra como lo están los modelos de la competencia. La firma de Mountain View presenta el Gemini 1.5 como un “modelo multimodal de tamaño medio” optimizado para adaptarse a un amplio abanico de tareas. La razón por la que funciona de manera similar al 1.0 Ultra es porque aplica muchos modelos más pequeños como parte de una arquitectura para tareas específicas. Google logra el mismo rendimiento con un LLM más pequeño utilizando un marco cada vez más popular conocido como "Mezcla de expertos" o MoE. Basado en dos elementos clave de la arquitectura, MoE superpone una combinación de pequeñas redes neuronales y ejecuta una serie de enrutadores de redes neuronales que impulsan dinámicamente los resultados de las consultas. “Dependiendo del tipo de entrada, los modelos MoE aprenden a activar selectivamente las vías expertas más relevantes en su red neuronal. Esta especialización mejora significativamente la eficiencia del modelo”, explicó Demis Hassabis, director ejecutivo de Google DeepMind, en una publicación de blog. "Google ha sido uno de los primeros en adoptar y pionero de MoE para el aprendizaje profundo con investigaciones como Sparsely-Gated MoE, GShard-Transformer, Switch-Transformer, M4 y más", agregó el CEO. .
La arquitectura MoE permite al usuario ingresar una gran cantidad de información, pero también procesar estos datos con muchos menos ciclos de cálculo durante la fase de inferencia. Luego puede proporcionar lo que Dekate llama “respuestas hiperprecisas”. "Los competidores de Google están tratando de mantenerse al día, pero no tienen DeepMind ni la capacidad de GPU que tiene la empresa para ofrecer resultados", dijo Dekate. Con la función de comprensión del contexto extenso, Gemini 1.5 tiene una ventana emergente de 1,5 millones de palabras clave, lo que significa que un usuario puede escribir una sola oración o descargar varios libros de información en la interfaz del chatbot y recibir a cambio una respuesta específica y precisa. A modo de comparación, Gemini 1.0 tenía una ventana emergente de 32.000 tokens. Los LLM de la competencia generalmente se limitan a ventanas emergentes de alrededor de 10 000 tokens, con la excepción de GPT 4, que puede aceptar hasta 125 000 tokens. Gemini 1.5 Pro viene con una ventana emergente estándar de 128.000 tokens. Sin embargo, Google permite que un grupo limitado de desarrolladores y clientes empresariales lo prueben como una vista previa privada con una ventana emergente de hasta 1 millón de tokens a través de AI Studio y Vertex AI. "A medida que implementamos la ventana emergente de 1 millón de tokens, estamos trabajando activamente en optimizaciones para mejorar la latencia, reducir los requisitos computacionales y mejorar la experiencia del usuario", dijo Demis Hassabis, director ejecutivo de Google DeepMind.
Si quieres conocer otros artículos parecidos a Google turboalimenta su motor GenAI con Gemini 1.5 puedes visitar la categoría Otros.
Otras noticias que te pueden interesar